












公式サプライヤー
公式および認定ディストリビューターとして200社以上の開発元から正規ライセンスを直接ご提供いたします。
当社のすべてのブランドをご覧ください。
英語で読み続ける:
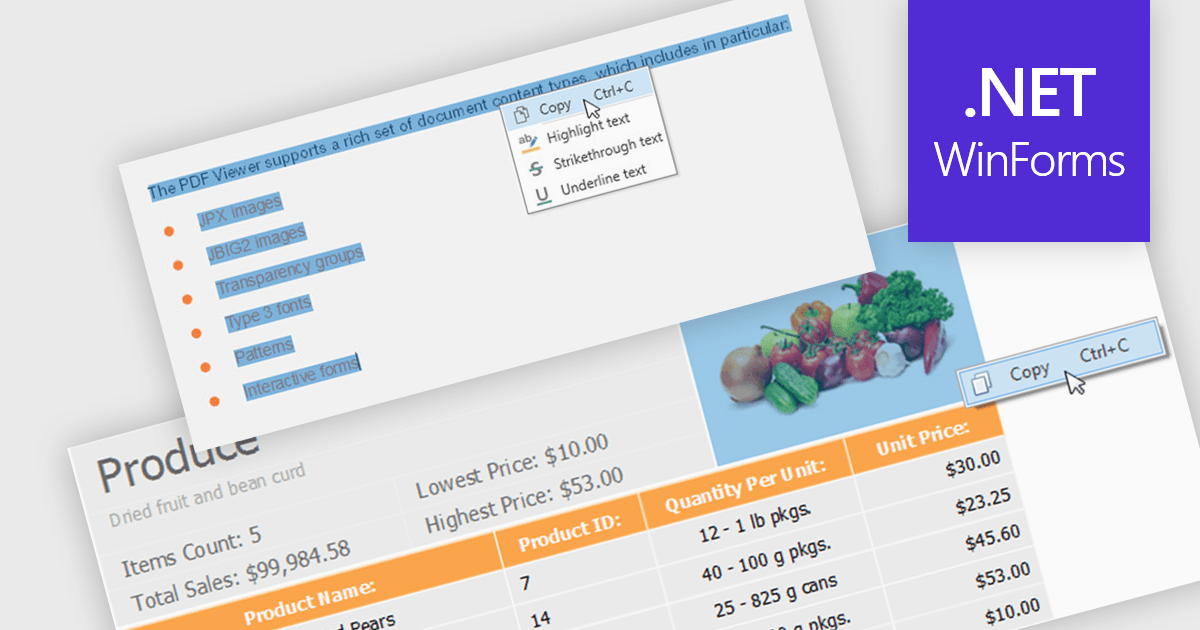
Extracting content using a PDF Viewer refers to enabling end users or applications to select and retrieve content directly through the viewer’s user interface, based on interactive actions such as text selection, area selection, or page-level capture. For software developers, this means the viewer acts not only as a rendering surface but also as a controlled extraction layer that exposes selected text, images, or regions. This approach is valuable in review, approval, and data capture scenarios because it reflects explicit user intent, aligns extracted data with what is visibly selected on screen, and avoids reliance on background parsing alone, resulting in more predictable and user-driven content retrieval within applications.
Several WinForms PDF Viewer components allow content extraction, including:
For an in-depth analysis of features and price, visit our comparison of WinForms PDF Viewer components.
電話: (888) 850 9911
Fax: +1 770 250 6199




